Vor ungefähr 10 Jahren habe ich eine Webseite mit einer Pre Datenbank an den Start gebracht. Diese Webseite habe ich dann für ca. 3 Jahre betrieben und dabei vieles gelernt. In diesem Text möchte ich ein wenig von den Herausforderungen beim Betrieb der Seite erzählen. Zum Teil, weil die Warez Szene ein faszinierendes Thema war und ist, aber auch weil ich es aus technischer Sicht interessant finde. Über die Jahre kamen da ein paar durchaus kreative Lösungen zusammen.
Hinweis: Ich habe eine ganze Menge technische Details und Erklärungen mit aufgenommen. Daher ist der Artikel etwas länger geworden. Also schnappt euch eine Mate bevor ihr anfangt zu lesen.
Ein kurzes Intro in die (damalige) Warez Szene
Für das Verständnis dieses Textes ist es nötig eine paar Grundbegriffe aus der Warez Szene der 1990er und 2000er Jahre zu kennen. Ich fasse das hier nur grob zusammen um den Text nicht zu lang werden zu lassen. Einen guten Einstieg bietet außerdem die englische Wikipedia in diesem Artikel: Nuke (warez)
In der Warez Szene werden Filme, Computerspiele, Musik, etc. von Release groups veröffentlicht. Jede einzelne Veröffentlichung nennt man ein Release. In der Regel werden die Releases auf einen FTP Server geladen. Ein solcher Server wird als Site bezeichnet. Große Teile der Kommunikation innerhalb der Szene finden im IRC Netzwerk statt. Zu jedem neun Release gibt es eine "Ankündigung" in einem speziell dafür bereitgestellten IRC channel. Diese speziellen Chat-Räume werden Pre channel genannt. Zusätzlich werden alle Releases in einer Datenbank gesammelt, der sog. Pre database oder kurz PreDB.
In einer PreDB werden neben Titel und Zeitpunkt der Veröffentlichung noch ein paar zusätzliche Informationen gespeichert. Dazu gehören die Release group, die Größe (Anzahl der Dateien + Größe in MB/GB), eine Kategorie oder Section sowie ein Genre. Auch die Information ob und wieso ein Release zurückgezogen wurde wird ggf. in der PreDB gespeichert.
Zusätzlich zu diesen Information stellen die meisten Release groups eine NFO Datei zu jeden Release bereit. Dabei handelt es sich um eine kleine Textdateien die genauere Information zum Release beinhalten. Einen gewissen Kultstatus genießen diese Dateien weil sie häufig das "Logo" der Group in Form von ASCII Art beinhalten.
Betrieb einer PreDB/NFO Webseite
Nach dieser Einleitung ist es hoffentlich nun etwas einfacher zu verstehen worum es beim Betrieb einer PreDB Website geht. Ich habe eine Datenbank mit (mehr oder weniger) allen Releases online bereitgestellt. Diese Datenbank wurde ständig aktualisiert und war durchsuchbar. Zusätzlich wurden (sofern verfügbar) die NFO Dateien zu den jeweiligen Releases angezeigt.
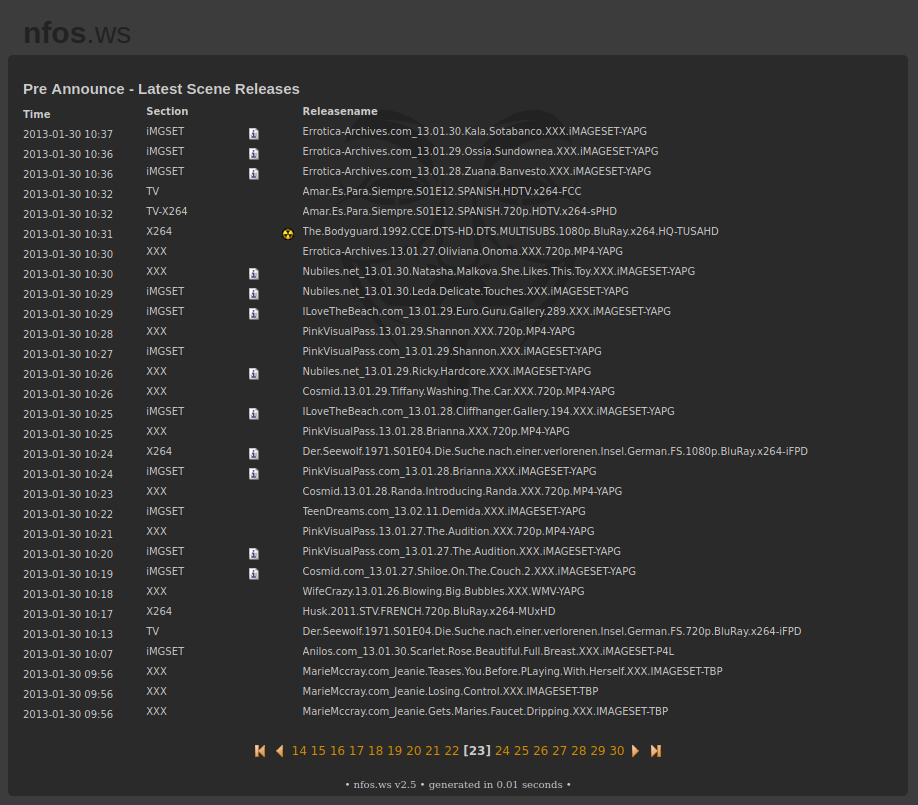

An dieser Stelle vielleicht noch ein wichtiger Hinweis: Auf der Webseite (und auch auf allen anderen PreDB Seiten) werden nie Downloads der eigentlichen Releases angeboten. Das ist eine komplett andere Baustelle.
Releases aus Pre Chans sammeln
Um die Datenbank ständig aktuell zu halten war es nötig die neuesten Releases aus den Pre Chans zu sammeln. Die Channel
selbst, sowie die Bots in den Channels, sind allerdings relativ "fragil". Mal wird ein Channel
geschlossen, mal ist ein Bot down. Der ein oder andere erinnert sich sicherlich auch noch an die sog. Net-Splits
im IRC. Die können ebenfalls dafür sorgen, dass man die Nachrichten aus einem Channel nicht mitbekommt.
Daher wurde mir schnell klar, dass es notwendig ist die Releases aus verschiedenen Pre Channels gleichzeitig zu sammeln.
Ein Teil des Projekts war somit ein "IRC Bot" bzw. ein Script welches ständig in mehreren Pre Chans anwesend war, und
dort die geposteten Releases gesammelt hat. Zu den Herausforderungen in diesem Bereich gehörte es sicherlich die
geposteten Releases vom Rest der Kommunikation im Channel sauber zu trennen.
Dazu hatte ich pro Channel ein (oder mehrere) reguläre Ausdrücke welche die Release-Announcements filterten.
Zusätzlich wurden nur Releases in die Datenbank aufgenommen, die in mindestens zwei Pre Chans unabhängig voneinander
gepostet wurden.
Das bedeutete im Umkehrschluss jedoch auch, dass das komplette System nur funktionierte wenn mein Bot in mindestens
zwei Pre Chans anwesend war. Daher habe ich den Bot in der Regel in 3-5 unterschiedlichen Channels lauschen lassen.

In einigen der Pre Channels war sämtliche Kommunikation verschlüsselt. Nur wem das aktuelle Passwort für den Kanal bekannt war konnte die Nachrichten lesen. Daher musste ich in den IRC Bot verschiedene Crypto-Alogorithmen implementieren - und je nach Channel aktivieren.
Grundsätzlich war das Aktualisieren der Datenbank mit neuen Releases eine eher einfache Aufgabe. Wesentlich schwieriger, war da schon das Sammeln der NFO Dateien.
Die ständige Jagd nach NFO Dateien
Einige der Pre Chans haben zu jedem Release auch eine NFO Datei bereitgestellt, sobald diese verfügbar war. Diese
Channels waren jedoch wesentlich seltener als diejenigen in denen nur die Releases an sich gepostet wurden.
Primär habe ich die NFO Dateien damals zwar über diese Channels, und den im vorherigen Abschnitt erwähnten IRC Bot,
gesammelt - es konnte aber nicht schaden auch noch andere Quellen zu nutzen.
Zwei dieser Quellen möchte ich hier erwähnen, weil sie aus meiner heutigen Sicht technisch ziemlich kreativ waren:
Der Usenet NFO Crawler
Viele der Releases incl. der NFO Dateien, landen früher oder später im Usenet. Daher kam ich auf die Idee "einfach" die Binary-Groups nach NFO Dateien zu durchsuchen, und diese dann den Releases in der Datenbank zuzuordnen.
Dazu eine extrem verkürzte und technisch sehr unsaubere Erklärung des Usenets:
Das Usenet ist im Prinzip nichts anderes als ein großes Forum in dem Textbeiträge geschrieben werden. Die Themen sind in verschiedene Gruppen (usenet groups) unterteilt. In jede Gruppe können Textbeiträge mit einem Subject und dem eigentlich Text geschrieben werden. Wenn man Texte lesen möchte schaut man sich zunächst die Titel/Subjects in einer Gruppe an, und kann dann entscheiden welche Texte man aufrufen möchten. Heute vielleicht am ehesten vergleichbar mit reddit.
Irgendwann kamen findige Hacker auf die Idee, dass Binärdateien im Prinzip auch nur Text sind, und man diesen Text
natürlich auch im Usenet posten kann. Newsgroups in denen ausschließlich Binärdateien gepostet werden nennt man
Binary-Groups.
Die Dateien werden dazu einfach in hunderte Teile zerlegt und dann in einzelne Beiträge geschrieben. Über die Subjects können diese später wieder zu einer Datei zusammengefügt werden.
Eine wesentlich ausführlichere Erklärung findet sich in der Wikipedia:
Usenet (Binary Content)
Wie findet man aber nun NFO Dateien in diesen zig-tausenden Binärtext-Beiträgen?
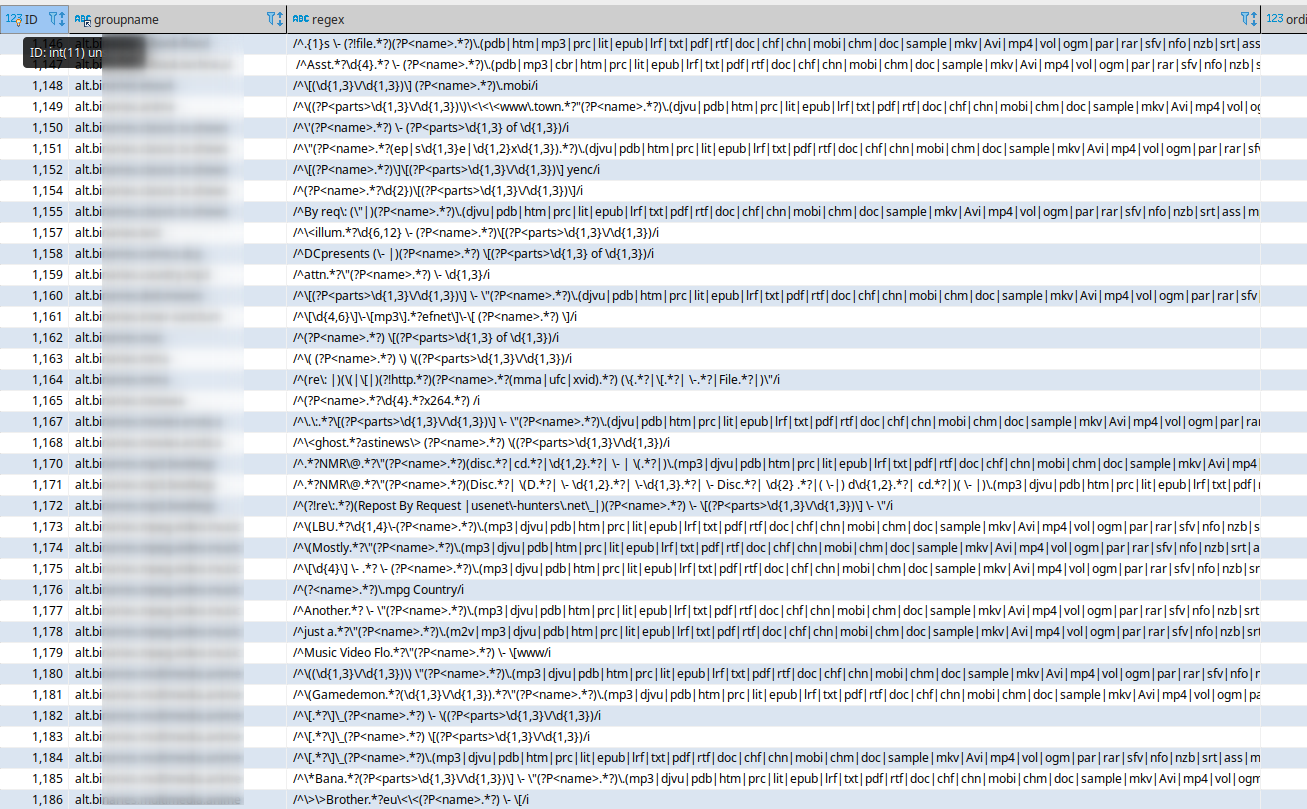
Auch dafür habe ich wieder einen Bot programmiert. Dieser ging permanent alle neu geposteten Beiträge in verschiedenen Binary-Groups durch, und versuchte zunächst zu identifizieren ob es sich um ein Scene-Release handelt. Dazu wurde das Subject jedes einzelnen Beitrags mit eine Liste von regulären Ausdrücken angeglichen. Wenn es hier einen Treffer gab, bestand eine hohe Wahrscheinlichkeit für eine Scene-Release. Der so gefundene Name wurde dann mit allen Releases in der Pre-Datenbank abgeglichen. Gab es auch hier einen Treffer war ein Release gefunden. Schlussendlich wurde nun noch geprüft ob es sich um eine NFO Datei handelt. Nur dann wurde der Inhalt des Beitrags (in diesem Fall also die NFO Datei) gespeichert, und dem Release in der Datenbank zugeordnet.
Auf dem Screenshot sieht man einen Ausschnitt aus der Tabelle in der die Regulären Ausdrücke für die verschiedenen Binary-Groups gespeichert waren.
Der Png2Nfo Crawler
Verschiedene Quellen stellten NFO Dateien nicht im Textformat sondern als PNG Bilder zur Verfügung. Zum einen gibt es dann keine Probleme bei der Darstellung, und zum anderen sollte so die Weiterverbreitung der ursprünglichen NFO Dateien unterbunden werden.
Um also weitere Quellen für NFO Dateien nutzen zu können habe ich mir überlegt, dass es gut wäre aus PNG Dateien "einfach" wieder den ursprünglichen Text zu generieren. (Das berüchtigte "Entwicker-Einfach" ;))
Das es möglich ist aus den PNG Dateien wieder Text zu generieren ist zwei wesentlich Eingenschaften des "ASCII Art" zu verdanken:
- Es werden nur Zeichen aus dem ASCII-Zeichensatz verwendet, was die Anzahl der nutzbaren Zeichen auf ca. 240 begrenzt.
- Zur Darstellung der Dateien werden nichtproportionale Schriften verwendet, wodurch jedes Zeichen im resultierenden Bild die gleiche Höhe und Breite hat.
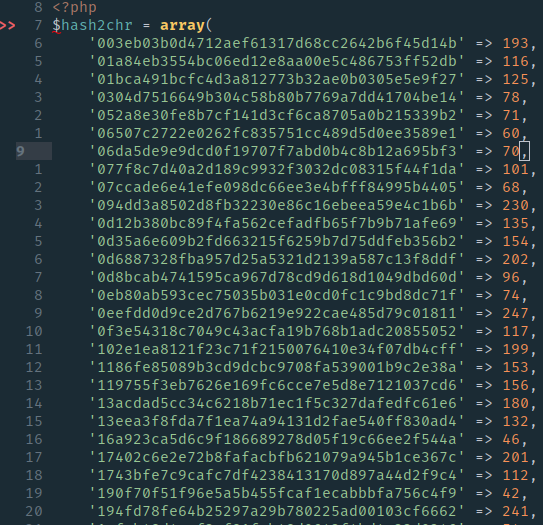
Um nun aus den PNG Dateien wieder Textdateien zu erstellen, ging ich folgendermaßen vor:
- Zunächst wurden einige der NFO-PNGs in viele kleine PNGs aufgeteilt, die jeweils ein Zeichen beinhalteten. In Handarbeit mussten, für jede Schriftart, diese ca. 240 Bilder einmal den jeweiligen ASCII Zeichen zugeordnet werden. Zusätzlich wurde für jedes Bild mit einem Zeichen ein Hash-Wert berechnet. Daraus entstand dann eine Tabelle die jedem ASCII-Zeichen in Bildform (via Hashwert) einen ASCII-Wert zuordnen konnte.
- Anschließend konnte ich mit einer simplen Software beliebige PNG Dateien in die jeweiligen einzelnen Zeichen zerlegen, daraus einen Hash-Wert bilden und über die Tabelle die jeweilige Nummer im ASCII Zeichensatz bestimmen.
- Schließlich wurden die so bestimmen ASCII Zeichen in eine Datei gespeichert und die "ursprüngliche" NFO Datei war rekonstruiert.
Hinweis am Rande: Heutzutage würde man das vermutlich Machine-Learning nennen. ;)
Technik und Performance der Webseite
Eigentlich alle Teile des Projekts habe ich mit PHP umgesetzt. Die Daten lagen in einer MySQL Datenbank.
An einigen Stellen musste ich jedoch von einer Standard PHP/MySQL Anwendung abweichen um eine vernünftige
Performance gewährleisten zu können.
Ich habe dieses Projekt als reines Hobby betrieben - weil ich es technisch interessant fand. Dadurch war ich bei der Auswahl der Hardware natürlich etwas eingeschränkt. Je billiger desto besser ;) Oder umgekehrt: Je performanter die Software, desto geringer die Kosten. Zusätzlich war ein 20€ VServer (oder Ähnliches) vor 10 Jahren natürlich lange nicht so leistungsstark wie heute.
Die Release-Datenbank umfasste etwa 4,5 Millionen Einträge. Dazu etwa 400.000 NFO Dateien und eine wenig "Nuke History". Insgesamt war die Datenbank ca. 1GB groß. Heute würde ich die Tabellen vermutlich einfach in den RAM laden und die Seite wäre wunderbar schnell. Vor 10 Jahren, und mit wenig Budget, war das etwas komplizierter.
Sphinx als Suchserver
Um die Datenbank performant durchsuchbar zu machen und das Navigieren durch die Releases (mit verschiedenen Filtern) zu beschleunigen, habe ich neben den MySQL Indexen einen Sphinx Suchserver aufgesetzt. Dieser erzeugte weitere Indexe aus den Daten in der MySQL DB, welche ich dann in PHP verwenden konnte. So konnte ich z.B. bei Paginieren durch eine bestimmte Kategorie von Releases, zunächst die Primärschlüssel der betreffenden Releases aus dem Sphinx-Index anfragen, um dann ein wesentlich performanteres Query auf die MySQL Datenbank fahren zu können.
Gearman und Redis für Usenet Crawler
In den Binary-Gruppen des Usenets kommen tausende neue Beiträge pro Minute hinzu. Selbst nur die Header der neuen
Beiträge periodisch zu crawlen, ist mit einem einfachen single threaded PHP Script nicht möglich. Daher habe ich hier
auf Gearman gesetzt. Damit kann man relativ einfach "Worker" erstellen, welchen dann parallel an
einer Aufgabe arbeiten können. (Ich habe dazu vor Jahren schon mal
etwas geschrieben)
Für die Koordination und Kommunikation der Worker habe ich eine Redis Datenbank eingesetzt, was auch recht gut
funktionierte.
Abschließende Worte
Nach wie vor finde ich die Technik und Organisation der Warez Szene faszinierend. Relativ einfache und über viele Jahre
erprobte Software und Protokolle (IRC, FTP, Usenet, ASCII, ...) wurden und werden hier seit vielen Jahren erfolgreich
eingesetzt.
Während der Zeit in der ich dieses Projekt betrieben habe, habe ich technisch extrem viel gelernt. Ich musste mich
mit verschieden Protokollen auseinandersetzt, diverse Bots programmieren, performante Software schreiben und vieles
mehr. Kurzum: Es hat extrem viel Spass gemacht!
Aufgehört habe ich irgendwann weil es extrem viel "Arbeit" ist hier am Ball zu bleiben. Die ständige Suche nach Pre-Chans, NFO Quellen, u.s.w. nimmt eine Menge Zeit in Anspruch. Man muss in den entsprechenden IRC Channels mitlesen und mit den Leuten in Kontakt bleiben um auf dem "Stand der Dinge" zu bleiben. Die komplette Szene ist zwar einerseits recht "konstant", anderseits aber auch sehr schnelllebig.
Damit schließe ich diesen Text, den ich schon lange einmal schreiben wollte.
Hach ja... Good old times...